
 [Cloudera - 10] pyspark 쉘에서 HDFS 파일 wordcount
[Cloudera - 10] pyspark 쉘에서 HDFS 파일 wordcount
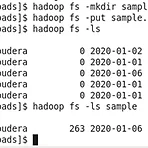
이전 글에서 사용했던 여러 함수들을 사용해 간단한 예제 텍스트 파일을 HDFS에서 불러와 wordcount를 직접 해보겠습니다. 먼저 아래 링크에서 sample.txt 파일을 가상머신 내부에 설치해줍니다. 파일 링크http://ailab.ssu.ac.kr/rb/?c=8/29&cat=2016_1_%EB%B9%85%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B6%84%EC%82%B0%EC%BB%B4%ED%93%A8%ED%8C%85&uid=797 A.I Lab - Spark #1 강의자료관리자 | 2016.05.09 | 조회 591ailab.ssu.ac.kr sample.txt 파일이 있는 Downloads 디렉터리로 들어가서 파일을 HDFS에 put 해줍니다. 이제 pyspark 쉘에 들어가서 ..
Development/Big Data
2020. 1. 7. 22:40
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
링크
TAG
- 알고스팟
- import
- 팰린드롬 구하기
- microwaving lunch boxes
- Jaeha's Safe
- hive
- Hadoop
- C++
- 하둡
- 배열과 문자열
- 스파크
- 삼각형 위의 최대 경로
- Django
- 외발 뛰기
- python
- 완전탐색
- Sqoop
- pyspark
- 분할정복
- 코딩인터뷰 완전분석
- 두니발 박사의 탈옥
- 백준
- HDFS
- 출전 순서 정하기
- 종만북
- 하이브
- 삼각형 위의 최대 경로 수 세기
- HiveQL
- 합친 lis
- 2225
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
글 보관함