
티스토리 뷰
Sqoop은 MYSQL, Oracle, Postgresql과 같은 RDBMS와 HDFS, Hive, Hbase와 같은 하둡 에코시스템 사이에서 데이터를 주고 받을 수 있게 해줍니다.
이번 글에서는 MYSQL에서 HDFS로 스쿱을 사용해 데이터를 import하는 방법에 대해 알아보겠습니다.

먼저 quickstart에 설치되어있는 MYSQL에 접속하기위해 mysql -u root -p를 입력하고 패스워드는 cloudera를 입력해줍니다.

show databases를 해보면 이미 여러 database가 있는 것을 확인할 수 있습니다.

이번에 사용할 데이터는 retail_db라는 database에 있는 테이블을 사용합니다.
use retail_db로 retail_db를 선택하고 show tables를 통해 들어있는 테이블들을 확인해봅니다.

MYSQL의 show databases 명령과 동일한 명령을 아래 sqoop 명령어로 확인할 수 있습니다.

아래 스쿱 명령은 show tables와 동일합니다.

이제 MYSQL에서 확인했던 retail_db의 customers라는 테이블을 HDFS로 import합니다.
database는 localhost/ 뒤에 입력해주고 table은 --table 옵션에 입력해줍니다.
--fields-terminated-by 라는 옵션에 '\t'라고 하는 것은 탭 간격으로 field(column)들을 구분시켜 준다는 뜻입니다.

import 명령어를 정상적으로 실행하면 쭉 실행하다 맵리듀스를 진행하는 것을 확인할 수 있습니다.
스쿱도 하둡과 마찬가지로 import, export에 대한 job을 맵리듀스로 실행합니다.

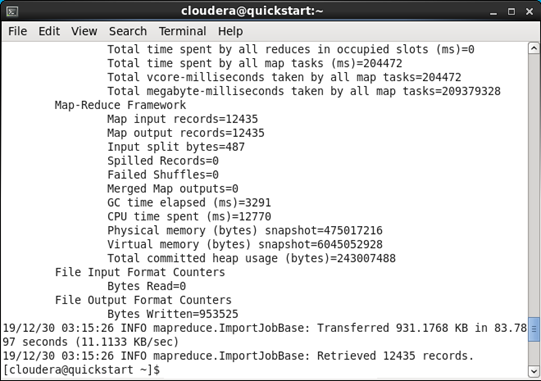
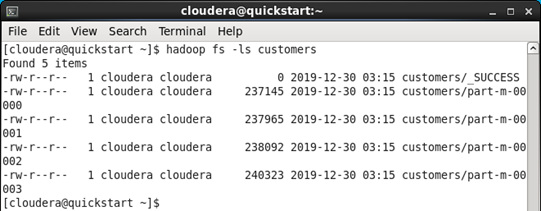
import를 마치고 HDFS내에 customers 데이터들이 정상적으로 이동된 것을 확인할 수 있습니다.

'Development > Big Data' 카테고리의 다른 글
| [Cloudera - 5] Sqoop으로 MYSQL에서 Hive로 import하기 (0) | 2020.01.01 |
|---|---|
| [Cloudera - 4] HDFS 데이터를 Hive로 옮기기 (0) | 2020.01.01 |
| [Cloudera - 2] Hadoop 기본 명령어 (0) | 2020.01.01 |
| [Cloudera - 1] Virtual Box로 Cloudera quick start사용해보기 (0) | 2019.12.27 |
| [Hadoop] Map Reduce (0) | 2019.12.27 |
- Total
- Today
- Yesterday
- 외발 뛰기
- 스파크
- Jaeha's Safe
- 종만북
- Django
- 하이브
- 합친 lis
- 삼각형 위의 최대 경로
- hive
- 팰린드롬 구하기
- Hadoop
- python
- import
- 하둡
- 출전 순서 정하기
- 삼각형 위의 최대 경로 수 세기
- Sqoop
- 배열과 문자열
- pyspark
- C++
- HDFS
- 2225
- 분할정복
- 백준
- 두니발 박사의 탈옥
- 완전탐색
- HiveQL
- microwaving lunch boxes
- 알고스팟
- 코딩인터뷰 완전분석
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |