
티스토리 뷰
quickstart 가상머신에서 스파크를 사용하려면 pyspark라는 명령어로 pyspark 쉘에 접근할 수 있습니다.
하지만 파이썬 2.6 버전과 스파크 1.6 버전으로 낮은 버전을 사용하기 때문에 버전을 높이거나 주피터 노트북과 같은 환경을 새로 구축해서 사용하기에는 어려운 점이 있어 스파크 함수들을 익히는 정도의 간단한 실습용으로만 사용하는 것을 추천드립니다.


처음 쉘에 진입했을 때 SparkContext available as sc 라고 표시되있기 때문에 별도로 선언해주지 않아도 sc로 사용할 수 있습니다.
sc의 타입을 확인해보면 SparkContext로 나옵니다. 이 SparkContext를 이용해 RDD를 생성하고 여러 스파크 함수들을 사용할 수 있습니다.

먼저 파이썬의 데이터 타입들을 사용하여 RDD를 생성해보겠습니다.
dataXrange에는 xrange 타입으로 1부터 9까지의 정수가 들어가있고
dataRange에는 리스트로 11부터 20까지의 정수가 들어가있습니다.

parallelize()
앞에서 선언했던 변수들을 다음과 같이 RDD로 생성할 수 있습니다.

또는 RDD 생성 시 파티션을 나누는 인자를 추가할 수 있습니다.
아래의 xrangeRDDPart는 dataXrange 변수를 3개의 파티션으로 나눈 RDD를 생성하게 됩니다.

glom(), collect()
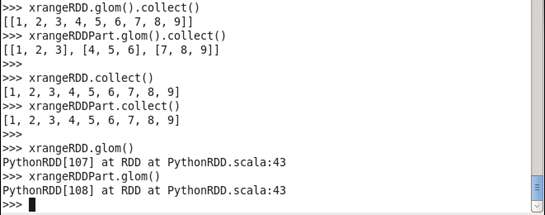
glom은 RDD의 데이터를 하나의 리스트로 모아줍니다.
collect는 데이터를 드라이버로 전달하여 출력시 확인 가능한 파이썬 데이터 타입 형태로 반환해줍니다.
그래서 RDD 출력을 할 때는 아래와 같이 glom().collect() 형식으로 사용하게 됩니다.
아래는 파티션을 나누지 않은 xrangeRDD와 파티션을 3개로 나눈 xrangeRDDPart를 출력하는 것을 확인할 수 있습니다.
여기서 collect만 사용하면 파티션 확인이 되지않는 하나의 리스트 내에 모든 데이터만 확인할 수 있고 glom만 사용하면 파이썬 데이터 타입으로 출력하지 않는 것을 확인할 수 있습니다.
map()
RDD를 선언했으면 스파크의 여러 함수를 사용할 수 있습니다.
그 중에 먼저 map 함수를 사용해보겠습니다.
map 함수는 어떤 함수를 인자로 받아 해당 RDD의 데이터들을 인자로 받은 함수에 적용시켜줍니다.
위에서 생성했던 1부터 9까지의 정수가 들어있는 xrangeRDD에 map을 적용합니다.
sub라는 입력 숫자의 -1을 반환해주는 함수를 map함수의 인자로 사용했고 출력 결과 각 숫자가 1씩 감소된 것을 확인할 수 있습니다.

flatMap()
map과 비슷하지만 map에서 이중 리스트로 표현되는 데이터를 하나의 리스트에서 전부 나열해줍니다.
아래 4개의 문자열이 있는 리스트를 RDD로 생성하고 동일한 lambda 함수를 인자로 각각 map과 flatMap을 사용합니다.
map을 사용한 RDD는 lambda 함수로 인해 문자열과 문자열 끝에 s가 붙은 문자열의 쌍으로 이루어져 있지만 flatMap을 사용한 RDD는 모든 문자열이 하나의 리스트안에 나열되어있습니다.
각 RDD를 count함수를 사용하면 결과가 다르게 나오는 것을 확인할 수 있습니다.
이렇게 모든 데이터를 하나의 리스트로 변환해주기 때문에 워드카운트와 같은 작업에 flatMap이 유용하게 사용됩니다.



'Development > Big Data' 카테고리의 다른 글
| [Cloudera - 10] pyspark 쉘에서 HDFS 파일 wordcount (0) | 2020.01.07 |
|---|---|
| [Cloudera - 9] pyspark 쉘에서 filter, groupByKey, reduceByKey, countByValue (0) | 2020.01.07 |
| [Cloudera - 7] KBO 한국 야구 데이터를 사용해 Hive에서 간단한 분석 해보기 (0) | 2020.01.03 |
| [Hadoop] 아파치 하이브 (0) | 2020.01.02 |
| [Cloudera - 6] HiveQL 기본 (0) | 2020.01.02 |
- Total
- Today
- Yesterday
- 종만북
- 출전 순서 정하기
- C++
- 알고스팟
- 백준
- python
- hive
- 합친 lis
- HDFS
- 두니발 박사의 탈옥
- 팰린드롬 구하기
- 삼각형 위의 최대 경로
- 하이브
- microwaving lunch boxes
- 하둡
- Jaeha's Safe
- Django
- 완전탐색
- 외발 뛰기
- Hadoop
- 스파크
- pyspark
- 분할정복
- 2225
- 코딩인터뷰 완전분석
- 삼각형 위의 최대 경로 수 세기
- import
- 배열과 문자열
- HiveQL
- Sqoop
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |