
 [Cloudera - 7] KBO 한국 야구 데이터를 사용해 Hive에서 간단한 분석 해보기
[Cloudera - 7] KBO 한국 야구 데이터를 사용해 Hive에서 간단한 분석 해보기
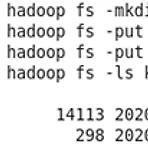
지금까지 했던 실습을 바탕으로 KBO 야구 데이터를 Hive에 옮기고 HiveQL로 간단한 분석을 해보겠습니다.먼저 아래 링크에서 첨부파일을 가상머신 내에서 다운받고 압축을 풀어줍니다. http://ailab.ssu.ac.kr/rb/?c=8/29&cat=2016_1_%EB%B9%85%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B6%84%EC%82%B0%EC%BB%B4%ED%93%A8%ED%8C%85&p=2&uid=770" data-og-host="ailab.ssu.ac.kr" data-og-source-url="http://ailab.ssu.ac.kr/rb/?c=8/29&cat=2016_1_%EB%B9%85%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B6%84%EC%82%B0%EC%..
 [Hadoop] 아파치 하이브
[Hadoop] 아파치 하이브
아파치 하이브란?하둡에 저장된 데이터(HDFS)를 SQL을 사용해 쉽게 처리하게 해주는 데이터웨어하우스(DW) 패키지입니다. 초기에는 Facebook에서 RDBMS로는 처리하기 힘든 대용량의 데이터를 처리하기 위해 개발했으며 현재는 아파치에 속해있는 오픈소스로 하둡 에코시스템의 일부가 되었습니다. HDFS를 처리하기 위해서는 맵리듀스를 Java나 Python으로 직접 작성해야 하는데 이러한 작업이 오래 걸리기 때문에 SQL만 알면 누구나 HDFS를 처리할 수 있도록 개발되었습니다. 하이브에서 사용하는 SQL은 HiveQL이라고 하는 SQL의 일부에 속하는 언어를 사용합니다.SQL과 거의 비슷하지만 Having절과 같은 일부 기능을 사용하지 못하는 특징이 있습니다. 하둡과 하이브에서의 작동방식을 간..
 [Cloudera - 1] Virtual Box로 Cloudera quick start사용해보기
[Cloudera - 1] Virtual Box로 Cloudera quick start사용해보기
Cloudera는 하둡 배포판(CDH)을 제공하는 기업입니다. Cloudera에서 제공하는 quickstart에서는 하둡과 에코시스템의 여러 프로젝트들이 설치되어있어 설치 삽질을 하며 시간을 잡아먹을 필요없이 하둡에 대한 실습을 바로 해볼 수 있습니다. 1. Virtual Box 다운로드https://www.virtualbox.org/wiki/Download_Old_Builds_6_0 Download_Old_Builds_6_0 – Oracle VM VirtualBox www.virtualbox.org해당 링크를 통해 Virtual Box를 다운로드 합니다. 현재 최신버전인 6.1 버전에서는 quickstart 이미지가 실행이 되지 않으므로 6.0 버전 밑으로 받으면 됩니다. 2. Clouder qui..
 [Hadoop] Map Reduce
[Hadoop] Map Reduce
Map Reduce는 하둡 클러스터의 데이터를 처리하기 위한 분산 프로그래밍 모델로써 대용량 데이터를 분산 컴퓨팅 환경에서 병렬로 처리하게 해줍니다. Map과 Reduce라는 두개의 메소드로 구성되어있으며 각 메소드는 프로그래머가 직접 작성하여 원하는 기능에 맞게 데이터를 처리할 수 있습니다. Map에서는 key-value 형식의 데이터를 읽어들여 필터링하거나 다른 값으로 변환하여 key-value의 list를 출력하는 작업을 수행합니다. Reduce에서는 Map에서 나온 결과값(key-value list)을 사용하여 새로운 key 기준으로 그룹화하고 집계연산을 수행하여 결과를 key-value의 list로 출력해줍니다. 이는 중복되는 데이터를 제거하고 원하는 데이터를 추출하는 작업으로서 RDBMS의 ..
 [Hadoop] HDFS
[Hadoop] HDFS
HDFS(Hadoop Distributed File System)는 하둡의 핵심 구성요소의 하나로써 데이터를 분산하여 저장시키는 파일 시스템 입니다. HDFS는 하나의 Name node(Master)와 여러대의 Data node(Slave)로 구성되어 있으며 file을 Block으로 분할하여 각 Block들을 Data node에 분산시켜 저장합니다.Block의 사이즈는 기본 65MB 혹은 128MB이며 file이 block의 크기보다 작을 때는 block 크기 전체를 사용하지는 않습니다. 이 때 Block은 복제되어 복제된 block들이 여러 노드에 하나씩 저장됩니다.default값은 3개이며 수정할 수 있습니다. 그리고 Name node에는 각 Bloock들이 어디에 위치해 있는지에 대한 정보를 포함..
 아파치 하둡이란?
아파치 하둡이란?
아파치 하둡이란? 대용량 데이터를 처리해주는 소프트웨어 프레임워크 입니다. 원래는 웹 검색 엔진이었던 아파치 너치(Apache Nutch)의 데이터를 관리하기 위해 개발되었습니다. 당시 너치는 수십억 웹 페이지를 크롤링하고 색인을 할 만큼의 데이터를 처리하는 기술이 없었지만 구글에서 공개한 GFS(Google File System)와 맵리듀스(Map Reduce)를 바탕으로 NDFS(Nutch Distributed File System)를 오픈소스로 구현하여 맵리듀스와 함께 너치에 적용할 수 있었습니다. 그리고 프로젝트가 점차 확장하여 독립된 프로젝트로 구성되었고 하둡과 같이 사용해 데이터를 관리할 수 있는 다양한 프로젝트들이 생겨나며 하둡 에코시스템이라는 하둡 생태계가 갖추어졌고 현재 다양한 기업에서 ..
- Total
- Today
- Yesterday
- 합친 lis
- python
- 두니발 박사의 탈옥
- 팰린드롬 구하기
- pyspark
- 종만북
- hive
- microwaving lunch boxes
- 삼각형 위의 최대 경로 수 세기
- 외발 뛰기
- 하둡
- import
- 분할정복
- 백준
- 알고스팟
- 출전 순서 정하기
- Jaeha's Safe
- 2225
- Hadoop
- 배열과 문자열
- 삼각형 위의 최대 경로
- Django
- 스파크
- Sqoop
- HDFS
- HiveQL
- 하이브
- 완전탐색
- 코딩인터뷰 완전분석
- C++
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |