
 우분투에 Django 설치
우분투에 Django 설치
우분투 환경에 Django를 설치를 위해 먼저 파이썬을 설치해야 합니다. 파이썬은 아나콘다로 설치하겠습니다. 1. 아나콘다 설치 해당 링크에서 아나콘다를 원하는 버전으로 설치합니다. 저는 Anaconda3-5.3.1-Linux-x86_64.sh 를 설치했습니다. https://repo.continuum.io/archive/ Anaconda installer archive repo.continuum.io 다운로드한 경로에 들어가서 파일의 실행권한을 아래 명령어로 입력하고 파일을 실행시켜 아나콘다를 다운로드합니다. 다운로드가 완료되고 버전을 확인하려는데 conda 명령어를 찾을 수 없다고 나옵니다. 이 때는 bashrc 파일에 들어가 파일의 맨 밑줄에 path를 아래와 같이 입력해줍니다. 이제 conda 명..
 우분투 노트북 덮개 닫아도 대기모드에 진입하지 않게 설정하기
우분투 노트북 덮개 닫아도 대기모드에 진입하지 않게 설정하기
서버로 사용중인 노트북이 대기모드로 진입해 중단이 되면 안되겠죠 노트북 덮개를 닫아도 전원이 계속 유지될 수 있도록 간단하게 설정을 바꿀 수 있습니다. 먼저 /etc/systemd/logind.conf 파일을 루트권한으로 열어줍니다. 파일을 열면 아래와 같이 여러 설정값들이 나와있는데 24번째 줄의 HandleidSwitch=suspend의 주석을 제거하고 suspend를 ignore로 바꿔줍니다. 그리고 아래 명령어로 systemd-logind를 재시작해주면 노트북 덮개를 덮어도 대기모드에 진입하지 않게됩니다.
 vim 줄번호, 들여쓰기 설정
vim 줄번호, 들여쓰기 설정
vim을 사용할 때 줄번호나 자동 들여쓰기와 같은 기능을 설정해놓으면 조금 더 편하게 vim을 사용할 수 있습니다. vimrc 파일에서 vim의 여러 설정들을 바꿀 수 있습니다. 먼저 vimrc 파일을 열면 아무것도 작성되지 않은 빈 파일이 나옵니다. 파일에 아래와 같이 작성해줍니다. 여기서 각 설정의 뜻은 autoindent = 자동 들여쓰기 nu = 줄번호 ts = 탭 넓이 shiftwidth = 자동 들여쓰기 시 탭 넓이 if has("syntax") = syntax를 가지는 파일이면 syntax 기능을 on
 안쓰는 노트북 우분투 서버로 구축하기
안쓰는 노트북 우분투 서버로 구축하기
프로젝트 진행으로 서버가 필요했는데 마침 집에 안쓰는 노트북이 있어 우분투 서버로 만들어봤습니다. 우분투 부팅용 usb와 노트북이 있고 공유기를 사용중이라면 쉽게 진행할 수 있습니다. 1. 우분투 부팅용 usb https://ubuntu.com/download/desktop Download Ubuntu Desktop | Download | Ubuntu Ubuntu is an open source software operating system that runs from the desktop, to the cloud, to all your internet connected things. ubuntu.com 링크에 들어가 우분투 이미지 파일을 다운받습니다. https://rufus.ie/ Rufus rufus..
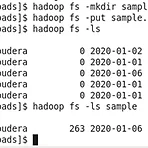 [Cloudera - 10] pyspark 쉘에서 HDFS 파일 wordcount
[Cloudera - 10] pyspark 쉘에서 HDFS 파일 wordcount
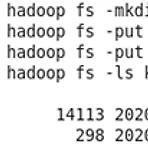
이전 글에서 사용했던 여러 함수들을 사용해 간단한 예제 텍스트 파일을 HDFS에서 불러와 wordcount를 직접 해보겠습니다. 먼저 아래 링크에서 sample.txt 파일을 가상머신 내부에 설치해줍니다. 파일 링크http://ailab.ssu.ac.kr/rb/?c=8/29&cat=2016_1_%EB%B9%85%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B6%84%EC%82%B0%EC%BB%B4%ED%93%A8%ED%8C%85&uid=797 A.I Lab - Spark #1 강의자료관리자 | 2016.05.09 | 조회 591ailab.ssu.ac.kr sample.txt 파일이 있는 Downloads 디렉터리로 들어가서 파일을 HDFS에 put 해줍니다. 이제 pyspark 쉘에 들어가서 ..
 [Cloudera - 9] pyspark 쉘에서 filter, groupByKey, reduceByKey, countByValue
[Cloudera - 9] pyspark 쉘에서 filter, groupByKey, reduceByKey, countByValue
filter()filter는 filter의 인자함수에서 true인 값만을 반환해줍니다.그러므로 filter에서 사용될 인자함수는 true나 false를 반환해주는 함수를 사용해야 합니다. 지난 글에서 생성했던 RDD입니다.filteredRDD에는 x보다 큰 값으로 filteredRDD2에는 x보다 작은 값으로 filter를 적용해줍니다. 기타 함수first() - RDD의 첫 번째 파티션의 첫 번째 요소를 반환합니다.take() - RDD의 첫 번째 파티션부터 인자로 넣은 정수만큼 반환합니다.takeOrdered() - 오름차순으로 인자값의 개수만큼 반환합니다.top() - 내림차순으로 인자값의 개수만큼 반환합니다. groupByKey()key, value 데이터 타입의 key 값을 기준으로 shuff..
 [Cloudera - 8] pyspark 쉘에서 RDD 생성과 map, flatmap
[Cloudera - 8] pyspark 쉘에서 RDD 생성과 map, flatmap
quickstart 가상머신에서 스파크를 사용하려면 pyspark라는 명령어로 pyspark 쉘에 접근할 수 있습니다.하지만 파이썬 2.6 버전과 스파크 1.6 버전으로 낮은 버전을 사용하기 때문에 버전을 높이거나 주피터 노트북과 같은 환경을 새로 구축해서 사용하기에는 어려운 점이 있어 스파크 함수들을 익히는 정도의 간단한 실습용으로만 사용하는 것을 추천드립니다.처음 쉘에 진입했을 때 SparkContext available as sc 라고 표시되있기 때문에 별도로 선언해주지 않아도 sc로 사용할 수 있습니다. sc의 타입을 확인해보면 SparkContext로 나옵니다. 이 SparkContext를 이용해 RDD를 생성하고 여러 스파크 함수들을 사용할 수 있습니다.먼저 파이썬의 데이터 타입들을 사용하여 ..
 [Cloudera - 7] KBO 한국 야구 데이터를 사용해 Hive에서 간단한 분석 해보기
[Cloudera - 7] KBO 한국 야구 데이터를 사용해 Hive에서 간단한 분석 해보기
지금까지 했던 실습을 바탕으로 KBO 야구 데이터를 Hive에 옮기고 HiveQL로 간단한 분석을 해보겠습니다.먼저 아래 링크에서 첨부파일을 가상머신 내에서 다운받고 압축을 풀어줍니다. http://ailab.ssu.ac.kr/rb/?c=8/29&cat=2016_1_%EB%B9%85%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B6%84%EC%82%B0%EC%BB%B4%ED%93%A8%ED%8C%85&p=2&uid=770" data-og-host="ailab.ssu.ac.kr" data-og-source-url="http://ailab.ssu.ac.kr/rb/?c=8/29&cat=2016_1_%EB%B9%85%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B6%84%EC%82%B0%EC%..
- Total
- Today
- Yesterday
- pyspark
- 두니발 박사의 탈옥
- Hadoop
- 외발 뛰기
- 합친 lis
- Django
- HDFS
- HiveQL
- 출전 순서 정하기
- 삼각형 위의 최대 경로
- C++
- import
- 2225
- 알고스팟
- 종만북
- 코딩인터뷰 완전분석
- hive
- 완전탐색
- 분할정복
- 백준
- Jaeha's Safe
- 스파크
- python
- Sqoop
- 하둡
- microwaving lunch boxes
- 팰린드롬 구하기
- 하이브
- 배열과 문자열
- 삼각형 위의 최대 경로 수 세기
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |